機械学習に関する最近のトピックとして、MLOpsというキーワードがあります。
このMLOpsについてはまだ明確な定義はできていませんが、今後機械学習に関わるに当たっては重要なキーワードになると思われます。
この記事では、MLOpsの概要から解説し、MLOpsがどのような課題を解決するためのプラクティスかを説明します。
また、よく使われるMLOpsのためのフレームワークやライブラリについても紹介します。
背景
2016年頃から、急速に機械学習を取り込んだシステムの開発や現実の問題への適用が一般的な企業にも広まってきた。機械学習を取り込んだシステムの開発が一般的になるにつれ、特に「MLOps」(DevOpsから派生した造語で、機械学習システムの運用周りを指す言葉)という考え方が重要視されるようになってきた。
機械学習を含むシステムの「技術的負債」
2015年にNeurIPSで発表された"Hidden Technical Debt in Machine Learning Systems"という論文がある。これは、機械学習を含んだシステムの「技術的負債」についていわゆるアンチパターンに言及した論文である。
この論文から引用される図として以下の図がある。
この図は、機械学習の予測アルゴリズムなどを記述するいわゆるモデリングと呼ばれる処理に関するコードを書くのは本当に一部でしかないということを表している。
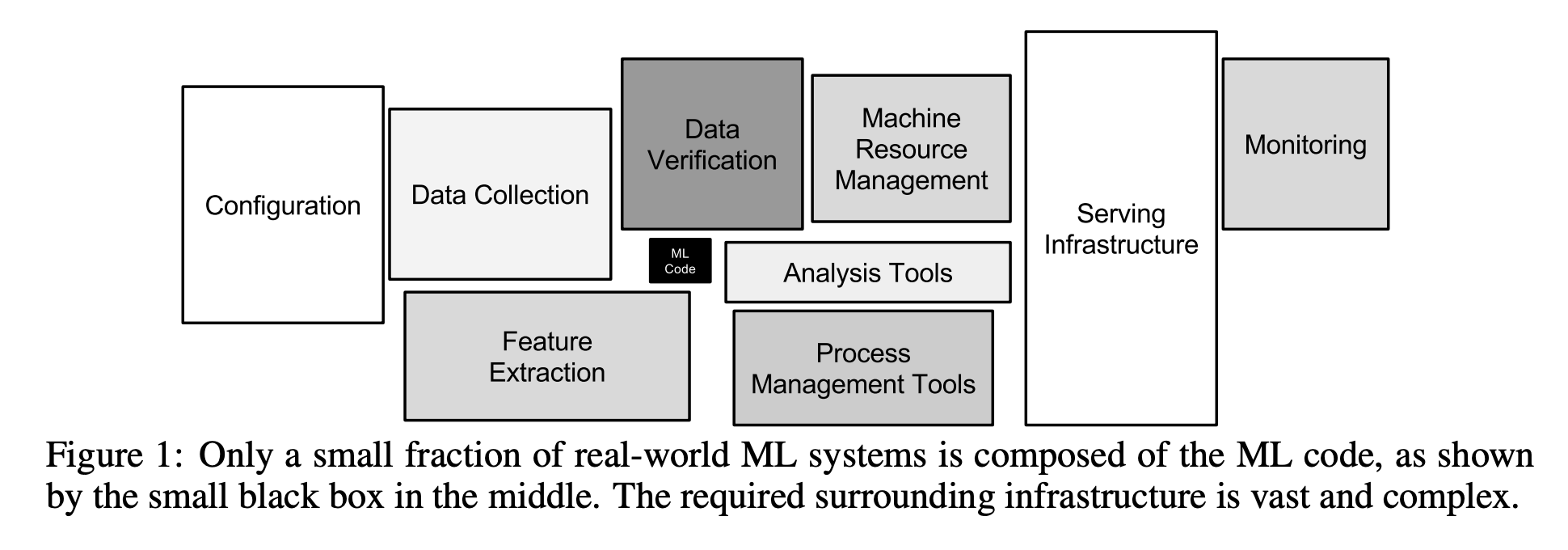
機械学習システムの構築・運用する上での課題
機械学習システムを構築・運用する上で直面するよくある課題としては。以下のような物があげられる。
データサイエンスとソフトウェア開発の違い
機械学習システムを構築する際、よく行われる体制として、
- データサイエンティストがDWH(データウェアハウス)から取得したデータを元にモデルを構築
- 機械学習エンジニア(またはソフトウェアエンジニア)が構築したモデルを本番環境に実装
という体制が取られることが多い。
このような開発体制の場合、以下のような課題が発生することが多い。
- データサイエンティストが作成したモデルのコードをそのまま本番環境の実装に流用できない
- 本番環境への実装を行うにあたり、モデルの予測だけでなくシステムとしてのエラーハンドリングなどを考慮する必要がある
このような課題が発生する背景としては、データサイエンスとソフトウェアエンジニアリングとで求められるスキルが異なることにも起因しています。
データサイエンスでは、データの分析やモデルの作成を使い慣れた道具でクイックに作成し、イテレーションを回して改善していくことを求められます。
そのため、メンテナンス性や再利用性の高いコードを書くことは優先順位が下がってしまいます。
一方で、機械学習システムを本番環境に実装するためにはソフトウェアエンジニアリングの知見が必要になります。構築した予測モデルから安定的に予測結果が得られること、システムとしてテスト可能なことなどが重要になります。
これらの原因からデータサイエンティストが作成したコードを素早く本番環境の実装に移植することが難しくなり、
- 機械学習システムの構築に時間がかかる
- 構築した機械学習システムの品質問題
といった課題につながります。
同一の結果を得ることが難しい
機械学習の予測モデルを扱う難しさの一つとして、ある一つの実験結果を決定的に常に再現するのが難しいという特徴がある。
これは、機械学習モデルの振る舞いが、与えられたデータに依存して決まることが大きな理由であり、また、データ自身も変化しうるため、CACE (Change Anything Change Evrything) 原理と呼ばれる。
機械学習システムは何かを少しでも変更すると、システム全体の振る舞いが変わってしまうという特性が知られている。
学習時と本番環境に実装した際の振る舞いが異なる原因として以下のような原因が存在する。
- ユーザ情報などのマスターデータが変化するなど、大規模データに対して過去のある時点での同一のデータを用意するのが困難
- ライブラリなど依存環境を再現するのが難しい
- 実験時と本番環境でのパイプラインに使われる言語やコードが異なる
- 入力データの分布や仮定が、学習時と本番で異なる
また、上記に加えて以下のような点から学習モデルを再度獲得するのが困難な場合もある。
- ハイパーパラメータなど設定の記録漏れ
- 学習にかかる時間やコストが非常に高く、経済的な理由で再実験が難しい
上記のような原因で、
- 作成したモデルを再現できない
- 本番環境で実行した時にモデル作成時とは異なる振る舞いをする
といった課題が発生する。
継続的な学習とサービング(機械学習システムの運用)
機械学習の予測モデルは入力データにより振る舞いが決まる。
ある学習モデルを使い続けるということは、暗黙のうちに以下の仮定を置いている。
- 入力データの分布は学習時と予測時で大きく変わらない
- 入力データの使える特徴量も、学習時と予測時で一致している
例えば、ECサイトなどであれば、サイトの回収や新商品の追加といった変化により、
以前に作成した予測モデルがうまく予測できなくなるといったことが発生する。
このように、長期的に利用する機械学習システムは、定期的に新しいデータを用いて予測モデルを更新することが必要である。
また、データが大規模になるとスクラッチからの予測モデルの学習に非常に時間がかかってしまうため、計算時間を低減する取り組みも必要となってくる。
MLOpsの問題意識
上記の機械学習システムに関する問題を踏まえて、MLOpsで扱う問題意識を整理すると、
以下の物が挙げられます。
-
役割の溝、組織の溝をどう埋めるか
データサイエンティストと機械学習エンジニア(ソフトウェアエンジニア)、データエンジニアなどのマインドセットや方向性の違いによる課題
-
機械学習システムの振る舞いを決めるデータの扱い
機械学習システムの振る舞いは入力されるデータにより決まる。
学習時の入力データに対する仮定が、本番でも適用できるのかということを検証し続ける必要がある。
このような問題に対して、MLOpsでは、モニタリング、バージョニング、データの検証などの対応を提供する。 -
決定的なテストの難しさ
予測モデルの学習時には乱択アルゴリズムをしばしば含んだり、パラメータにランダムに与える初期値に依存して大きく結果を変えることがある。そのため、決定的なユニットテストなどの自動テストが行いづらく、バグを見つけづらいという問題がある。
これに対しては、更新されたモデルに対して既知のデータセットとラベルを比較し、オフラインで予測性能を検証する方法が一般的である。加えてデータ自体が学習時と大きく変化していないかの検証も行うと良いことが知られている。
また、近年敵対的サンプルを使った予測モデルを騙すための考え方も注目されてきている。
-
本番環境への適用
データサイエンティストがモデルを作成する環境(実験環境)と実際の機械学習システムが動作する環境(本番環境)が異なることから以下のような問題が発生しうる。
- データの置かれる場所と実際に処理する場所が、データウェアハウスとラップトップと大きく異なり、ラップトップでは全データを扱いきれない。
- 実験は個人のラップトップで実施され、本番の処理はバッチ処理サーバなど異なる場所で実施されるため環境の再現・管理が煩雑となる
- データサイエンティストのコードが、本番環境で実行すると環境を壊してしまう恐れがある
- PythonやCで書かれたnativeコードなどの依存ライブラリがばらばらで、本番環境でコンフリクトが発生する
-
再現性をどうやって確保するか
様々な要因により、同じ実験を再現するのが難しいことがある。現実ではある時点でのスナップショットのデータに対して予測モデルを作成することとなる。
依存関係に関しては、近年ではDockerを使ったコンテナ技術の普及により、機械学習の環境をコンテナ化することで再現しやすくする方法が増えてきている。kubernatesと呼ばれるコンテナ化されたアプリケーションの管理、デプロイなどをするオーケストレーションシステムをベースとした、kubeflowと呼ばれる機械学習向けのパイプライン管理ツールも現れている。
再現性を確保することは、科学的な意義や本番環境での予測を安定的に行う事以外にも、属人性を低減させるというメリットが生まれる。
-
何をバージョン管理すべきか
一般的なソフトウェア開発では、Gitなどのバージョン管理システムを用いたソースコードの管理がされている。機械学習システムの開発においては、ソースコードの管理に加えて以下のバージョン管理を行うことが望ましい。
- モデルのバージョン管理
- パイプラインのバージョン管理
- データのバージョン管理
MLOpsの枠組み
MLOpsには上で示したような複数の問題意識があり、異なる文脈でMLOpsという言葉が使われています。どのような文脈かによってMLOpsが指す内容が異なることに注意が必要です。
機械学習システムの全体像
機械学習システムを実際に運用しようとした時のワークフローは以下のようになるかと思います。
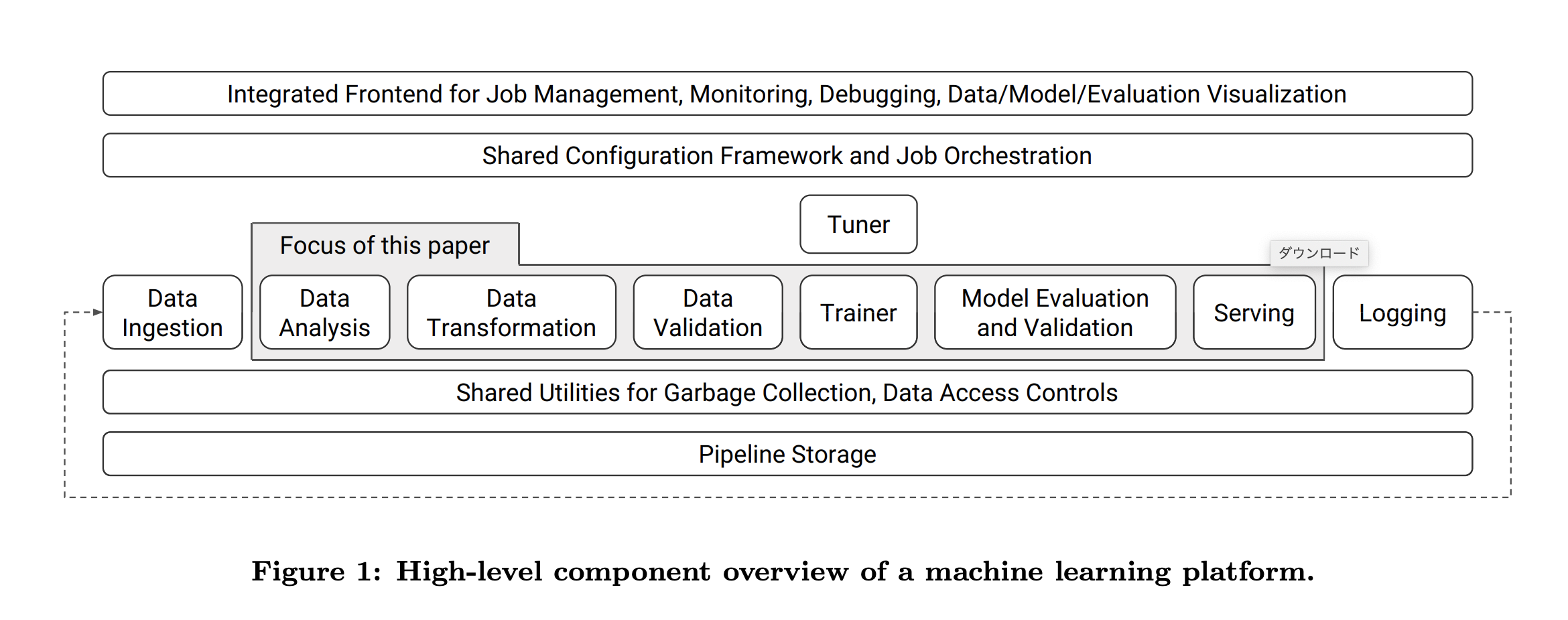
MLOpsに取り組む際には上図のワークフローを意識して考える必要があります。
具体的な技術要素
MLOpsの取り組みについて、具体的な技術要素について紹介していきます。
データ収集と特徴量管理
データの収集から学習に使用する特徴量の管理については、以下のような技術要素があります。
-
データ基盤
機械学習システムを構築する上で、データ基盤は非常に重要になります。
データが中央管理されていない場合、学習のために都度データの収集を行うことになり、
学習を開始するまでに多大な労力を必要とします。
データウェアハウスやデータレイクといったデータ基盤が構築されていれば、データサイエンティストは都度必要なデータを利用することができ、開発効率が格段に上がります。
さらにデータウェアハウスなどは、生データから特徴量を計算した結果を保存してく先としても有効です。よく使用されるものとして、AWSのRedShiftやGCPのBigQuery、AzureのCosmosDBやTreasureDataなどがあります。
-
データパイプラインの構築
実際の機械学習システムでは生データをそのまま使うことは稀です。ほとんどの場合、生データからクレンジングや正規化などの前処理を行った上でモデルに入力されます。
本番環境で推論を行う場合にも学習時と同様のデータの加工が必要になります。このように、データを生データから加工しモデルに入力するまで加工するパイプラインは学習でも推論でも必要になります。そのため、データパイプラインを標準化して共有することは有効です。
このようなパイプラインを構築するライブラリとして、Apache Airflowやluigiなどのワークフローライブラリがよく使用されます。
また、クラウドのマネージドサービスではAWSのGlueやData Pipeline、GCPのDataflowがあります。
-
ラベリング
多くの機械学習のシステムは教師あり学習を採用している場合が多いですが、その学習のためには教師データのラベリングが必要になります。
ラベリング作業は手作業で行うことが多く、非常にコストが高く、機械学習のワークフローとは切り離されて考えることが多いです。
しかし、最近ではactive learning(能動学習)やsemi-supervised learning(半教師あり学習)によって、効率よく教師データを生成できる場合があります。これらの技術により、機械学習のフローの中にラベル付きのデータ生成を含めることが可能になる場合があり、ML基盤として構築できる可能性があリます。 -
特徴量リポジトリ
組織の中で使用される機械学習モデルでは、特に同一のデータソースを使用している場合、同じ特徴量を使用することが多くなります。これらの特徴量の生成は同様の処理を複数のモデルで使用するため、共通化することで効率化することができます。
また、共通化した特徴量を検索できるような仕組みも合わせて必要になります。このように特徴量に関する変換と、変換した特徴量を組織で共有できる仕組みは、機械学習モデルの開発効率の向上に繋がります。 -
モデルの構成管理
適切なデータ基盤やパイプラインの共通化、特徴量リポジトリがあれば、モデルについて推論結果や使用した特徴量だけでなく、推論プロセスや学習などについても管理することが可能になります。
-
Backfill
機械学習のモデルは日々新しいものが作られていき、その過程で新しい特徴量を開発・使用することがあります。 当然、これまでにない特徴量なので、過去のデータに対してそれを適用させていく必要が出てきます。
こうしたモデルをプロダクションにしていくには、データウェアハウス内のデータなどに特徴量を自動で事前計算していくことが望まれます。 このbackfillについては、Airflowのようなワークフローライブラリで整備していくことが現状では有望だと考えられます。
-
データのバージョン管理
機械学習では、度々過去のデータにさかのぼって検証したい状況が発生します。 この時、各モデルが学習されたときの正確な状況をそのまま管理しておかないと、モデルの再現性が取れなくなってしまいます。 そのため、モデルのコードだけでなくデータについても適切にバージョン管理することが求められます。
データのバージョン管理ツールとしてDVCなどが挙げられます。
実験管理とモデルのデプロイ
機械学習の開発においては、多数の実験(学習モデルの作成)が行われます。
こうした実験について適切に管理を行い、優れたモデルを正しく本番環境に適用していくことには、MLプラットフォームに求められる大きな機能と考えられます。
例えば、実験ごとに使用したデータやハイパーパラメータの値を管理しておくことなどが挙げられます。
-
実験のロギングと可視化
機械学習モデルの開発には、モデルの最適なパラメータを探索するために膨大な量の実験が行われます。これらの実験結果を管理することは非常にコストが大きく、機械学習システムの開発のボトルネックになりかねません。
そのため、実験のパラメータとその時の結果をセットで管理して、それらを可視化する機能がMLOpsプラットフォームとして提供される場合が多いです。
-
モデルのバージョン管理
実験管理と合わせて、モデル自体のバージョン管理も行われることも多いです。モデルをバージョン管理すると、データサイエンティストや機械学習エンジニアは過去のモデルについて再現を行うことができる様になります。
管理の仕方は様々で、Pythonのpklなどのモデルファイルの形式で管理する場合もあれば、Dockerコンテナを管理する場合もあり、これらは自動で管理されます。
-
特徴量の自動生成
特徴量エンジニアリングは、機械学習モデルの開発において非常に時間のかかるタスクです。 多くの場合、これに時間がかかるのはデータ収集やその変換に非常に時間がかかっています。 この作業のいくつかはデータサイエンティストの勘と経験、ドメイン知識が必要になりますが、その他の特徴量については自動化することが可能になる場合があります。 この作業を自動化することで、時間のかかる特徴量エンジニアリングの負担を軽減することができます。
-
ハイパーパラメータの自動調整
機械学習のモデルには一般にハイパーパラメータによって精度が左右されます。ハイパーパラメータの自動調整ツールがプラットフォームに組み込まれていれば、データサイエンティストは、よりモデルリング(アルゴリズムの開発)に集中することができます。
-
workflow管理
学習では膨大な数の実験を行い、その過程で中間生成物を作成し、評価することになります。これらは規模が大きくなるにつれ、管理する工数も大きくなり、不具合を生み出す原因になります。そのため、Apache AirflowやKubeflowに代表されるような自動化されたワークフローは効率と信頼性のために非常に重要な機能になります。 優れたMLプラットフォームには必ず強力なワークフローの概念があり、これらを取り込むことは非常に重要なことです。
-
コーディング環境の整備と標準化
MLプラットフォームでサポートする機械学習モデルとフレームワーク、モデルのコーディング環境については明確な指針があるべきです。 一般にNotebookをデータサイエンティストは好み、エンジニアはプロダクションレディな標準コードを好む傾向があり、これらの乖離は早期に解決することが望ましいです。
-
フレームワークのサポート
フレームワークのサポートについては組織ごとにまちまちです。多くのツールをサポートするべきと考える組織もあれば、限られたツールを深く使っていくことを良しとする組織もあります。これは組織及び機械学習システムがどの様な機能を必要としているかに依存するので、一概に言うことはできません。
モデルのデプロイと性能監視
実際の機械学習システムでは、モデルの精度だけでなく、実行速度や信頼性、その他制約が発生します。本番環境で入力されるデータにおいて問題なく稼働しているか、そして想定した予測精度を達成できているかを監視する必要があります。
-
モデルのデプロイ
MLプラットフォームは基本的にスケーラブルで最初から最後まで一貫して管理できるように構成されるべきです。マルチテナントの環境でライブラリの依存関係を再現することは難しく、デプロイの機能を整備することが求められます。多くの場合、デプロイはpklやコード、コンテナなどの形式でデプロイされ、これら一般的にgRPCやRESTやその他のメッセージング形式によって、APIとして動作するようになっています。
モデル配信には多くの場合、ルーティングやロードバランシングなどの機能ができることから、Kubernetesが使われることが多く、例としては、AlgorithmiaやSeldonなどがあります。
-
モデル編成と評価
入力データの分布の変化などにより、モデルは時間とともに精度が低下していくため、そのパフォーマンスをモニタリングする必要があります。この基本的な性能監視機能はデフォルトで提供されるべきで、開発サイドとしてはこれをモデルやアプリケーションに応じて自由に拡張可能なようにAPIとして提供することが望ましいです。
基本的には、すべての特徴と予測のログとあとで行われるであろう分析のために記録しておきます。これらをダッシュボードとして表示し、長期間に渡ってそのパフォーマンスを監視できるようにする必要があります。
-
データバリデーション
モデルの精度だけでなく、本番環境でモデルに入力されるデータに対しても監視が必要です。モデルが学習時に使用したデータと本番環境で予測に使用しているデータの特徴量の分布を監視し、データの傾向の変化について監視する必要があります。データの傾向が著しく変化した際には、モデルについて再学習などのアクションを取ることが求められます。
フレームワークやライブラリなど
MLプラットフォームを構築するためのフレームワークやライブラリとしては以下のような物が挙げられます。
mlflow
mlflowは、実験管理や再現可能なコードのパッケージング、モデルのデプロイも含んだ広範囲をカバーしたプラットフォームです。
kubeflow
kubeflowは、Kubernetes上で機械学習環境を構築するためのものです。
具体的には以下のmanifestを含みます。
- JupyterHub (Jupyterを複数ユーザーで使えるようにしたもの)
- TensorFlow Training Controller (学習用の分散環境が簡単に構築できる)
- TensorFlow Serving (構築したモデルを公開できる)
そのほかのフレームワーク
上記で紹介したものの他にワークフローライブラリのApache Airflowやハイパーパラメータチューニングを行うHydraなどがあります。
用途や導入したいソリューションに合わせてフレームワークを選ぶ、またはフレームワークの1部の機能だけを使うなどが可能です。
まとめ
この記事では、MLOpsの概要と機械学習システム開発のどのような課題に対処するか、
MLOpsを構築するためのフレームワークについて紹介しました。