scikit-learnを使った決定木モデルの構築¶
scikit-learnを使って決定木でのクラス分類をやっていきたいと思います。
決定木分析¶
決定木は、データに対して、もっともデータをうまく分類できる特徴量の条件を次々と定義していき、その一つ一つの条件に沿って分類していく方法です。
決定木を使う利点は以下になります。
モデルの結果の解釈が容易¶
決定木はモデルの特徴量に対して条件を設定して、その条件に沿って分類していきます。
分類の条件を見ればモデルがどのような条件でデータを分類しているのかが分かるのでディープラーニングなどの手法と比べて解釈が容易です。
質的データから量的データまで様々な変数を扱える¶
決定木は特徴量に対して条件を設定するので、カテゴリカル変数も連続値の変数もモデルの入力とすることができます。
モデルを使用する際の前処理なども少ないので、扱いやすいモデルです。
外れ値に頑健¶
外れ値があっても、もっともうまく分類できる条件で、分類の条件を設定するので外れ値の影響が少ないのが特徴です。
以下ではワインの品種を分類するサンプルデータを用いて、scikit-learnの決定木を用いた学習のコードサンプルを紹介します。
ライブラリのインポート¶
必要なライブラリをインポートします。
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, roc_auc_score, confusion_matrix, precision_score, recall_score
import warnings
warnings.filterwarnings('ignore')
data = load_wine()
特徴量データと教師データの作成¶
load_wineで読み込んだデータはディクショナリ形式でデータが入っているので、
モデルに入力できるように、pandasのデータフレームとnumpy配列に読み込みます。
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
print(X.shape)
print(y.shape)
X.dtypes
トレーニングデータと検証用データの分割¶
scikit-learnのtrain_test_splitを使って、トレーニングデータの一部を検証用データとして分けておきます。
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
モデルの作成と学習¶
決定木モデルを構築します。
scikit-learnのDecisionTreeClassifierで良く使うパラメーターは以下になります。
| パラメーター変数 | 概要 | 設定可能な値 |
|---|---|---|
| max_depth | 木の深さを設定します。木の深さを浅く設定することで過学習を抑えます | 木の最大の深さを整数で設定します。(デフォルトはNone)Noneの場合は葉の全てのサンプルが1つのクラスになるか、ノードのサンプル数がmin_samples_split以下になるまで木を深くします。 |
| min_samples_split | 1ノードあたりのサンプル数を設定します。サンプル数を増やすことで過学習を抑えることができます。 | 整数か小数の値を設定できます。整数を設定した時は、1ノードあたりのサンプル数の最小値。小数を設定した時は、小数×サンプル数が1ノードあたりのサンプル数の最小値になります。(デフォルト値は2) |
| min_samples_leaf | 1 つのサンプルが属する葉の数の最小値 | 整数か小数の値を設定できます。整数を設定した時は、サンプルが属する葉の数の最小値。小数を設定した時は、小数×サンプル数がサンプルが属する葉の最小値になります。(デフォルト値は1) |
| max_features | 木を分割する時に考慮する特徴量の数 | 文字列で、'auto', 'sqrt', 'log2',か Noneを設定する(デフォルトはNone) |
| class_weight | クラスの数に偏りがある場合に、クラスごとの重みを調整する変数 | {class_label: weight}のdict形式か'balanced'が設定できる(デフォルトはNone(全てのクラスが同じ重み)) |
tree_clf = DecisionTreeClassifier(max_depth=3)
tree_clf.fit(X_train, y_train)
検証データでの精度の検証¶
検証データを使ってモデルの精度を検証します。
今回は正解率を出してみます。
y_pred = tree_clf.predict(X_val)
accuracy_score(y_val, y_pred)
検証データでの正解率は約94%でした。
決定木の可視化¶
決定木を可視化することができます。
以下のPythonのライブラリを使用するので、pipでインストールします。
pip install pydotplus
pip install graphvizまた、オープンソースのグラフ可視化ソフトウェア、 GraphVizをインストールする必要があります。
macでhomebrewを使って以下のコマンドでインストールできます。
brew install graphviz以下で決定木を可視化するためのライブラリをインポートします。
from io import StringIO
import graphviz
import pydotplus
from IPython import display
g = StringIO()
export_graphviz(
tree_clf,
out_file=g,
feature_names=data.feature_names,
class_names=data.target_names,
rounded=True,
filled=True
)
graph = pydotplus.graph_from_dot_data(g.getvalue())
display.display(display.Image(graph.create_png()))
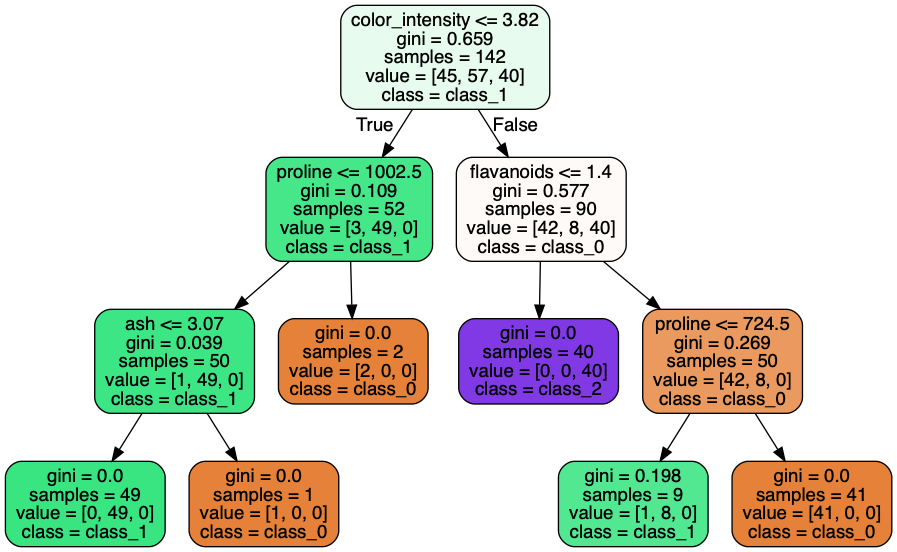
上の決定木の見方は、
1行目がノードを分ける条件になります。
例えば、一番上のノードは、「color_intensity」が3.82以下の時は左側のノードに分類し、残りは左のノードに分類されます。
2行目はそのノードのジニ係数になります。(ノードの不純度を表す指標です。不純度が最も低ければジニ係数の値は0,不純度が高くなればなるほどジニ係数の値が1に近づきます。)
3行目はそのノードのサンプル数です。
4行目はクラスごとのサンプル数です。
5行目はそのノードがどのクラスに分類されるかを表します。
まとめ¶
この記事ではscikit-learnの決定木を使ったクラス分類をワインのサンプルデータを使って紹介しました。
決定木は、解釈もしやすくどのような変数が分類や回帰の結果に影響しているかがわかりやすいので分析にも使うことができます。
また、モデルの学習と予測だけでなく、決定木の可視化方法についても紹介しました。
